
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 거대언어모델
- 챗GPT
- 생성AI
- 새책출간
- 머신러닝
- 서적집필
- U-Net
- AI그림
- ai
- 전이 학습
- 신규서적
- 오토GPT
- 그림AI
- 내손안에비서
- GPT-3.5
- 딥러닝
- 인공지능
- 생성모델
- Auto-GPT
- Generative AI
- 스테이블 디퓨젼
- Domain Adaptation
- gpt-4
- Stable Diffusion
- 모델 학습
- 도메인 적응
- 구글유입
- 쟈비스
- AutoGPT
- ChatGPT
- Today
- Total
코드 러너(Learner+ Runner)
거대 언어모델의 개인화 물결이 시작된 걸까? 본문
앞서 스테이블 디퓨전을 사용해서 세상에 존재하지 않지만, 실제 같은 사진들을 뽑았었다. 이 스테이블 디퓨전은 2022년 8월에 공개되었었는데, 이것이 특별한 이유는 깃허브에서 코드를 다운로드하여 개인 PC에서 사용할 수 있다는 점이다. 유사한 서비스인 미드저니와 DALL-E 시리즈는 모두 유료지만, 스테이블 디퓨전을 사용하면 퀄리티도 상당히 좋은 사진을 무료로 뽑을 수 있다는 점이 충격이다(물론 전기세는 들지만 말이다).

심지어는 최근 스테이블 디퓨전의 ControlNet 기능(기본 기능 중 하나는, 뼈대를 그리면 그대로 캐릭터가 생성된다..!)은 이미 미드저니와 DALL-E를 뛰어넘었다는 평가도 받는다. 그리고 이런 스테이블 디퓨전의 공개와 같은 일이 거대 언어 모델에서도 일어나기 시작했다..!
바로 LLaMA가 쏘아 올린 작은 공 'Alpaca'다..! 우선 배경을 설명하자면, 일반적으로 GPT-3과 같은 거대 언어 모델(LLM, Large Language Model)은 구축과 운영이 비싸다. 그래서 OpenAI와 같은 회사에 의해 구축되었고, 모델을 직접 받아서 사용하는 것이 아니라, API 형태로(유료로..!) 간접적으로 실행해야 했다. 학습 자체도 A100급 GPU를 사용했는데, 지난주 NVIDIA GTC 2023에서 공개했던 Hopper 시리즈를 제외하면 현재는 가장 프리미엄에 속하는 기업 대상 GPU가 A100이다. 문제는 이게 개당 8000달러가 넘는데(시점에 따라 다르긴 하다), 이걸 여러 개 사용해서 학습하므로 구축 비용이 비싸다.
이런 와중에 혜성같이 등장한 것이 Meta의 LLaMA다(논문: Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023)). 이 모델이 특별한 이유를 잠깐 간단히 살펴보자.
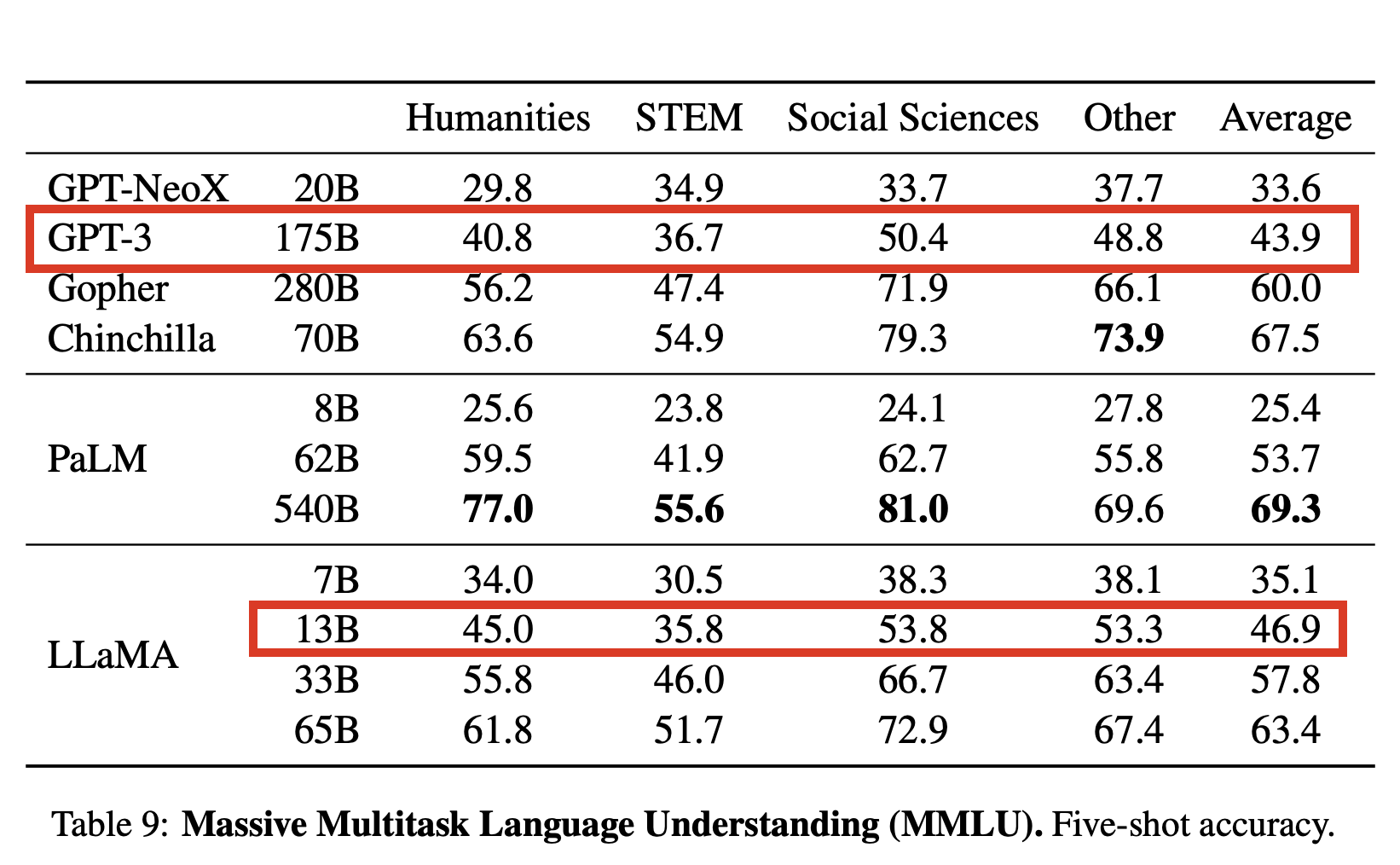
MMLU는 4지선다 문제를 얼마나 잘 맞히는지를 의미한다. 문제 예시를 보자.

아마 사람들도 못 푸는 사람 좀 나올 것이다. 재미있는 점은 다시 위의 성능 표로 돌아가보면, LLaMA가 130억 개 파라미터만 있어도 1750억 개 파라미터를 갖는 GPT-3 분량을 해낼 수 있다는 것을 보여준다(1B= 1 Billion = 10억).
그런데 여기서 한 가지 사건이 발생했다.

LLaMA를 사용하려면 메타 사이트에 들어가서 목적에 대해서도 작성해서 몇 가지 조건들에 동의 후 신청해야 한다(아직도 필자는 대기리스트에 올라가 있는 상태다..). 그런데 누군가 토렌트로 다운로드 가능한 버전을 올려서 많은 사람들이 다운로드한 것이다. 그래서 탄생한 것이 llama.cpp이다!

불가리아에 사는 Georgi Gerganov가 작업한 이 llama.cpp는 4-bit 양자화 기술이란 것을 이용해서 맥북에서도 라마를 돌리는 것을 목표로 했다고 한다. 그리고는 7B 모델을 4GB 크기로 줄이고, 13B 모델(아까 GPT-3에 버금가는 능력을 보여줬던 바로 그 모델..!)은 8GB 이하로 줄여버렸다. 모델이 크면 그래픽카드 VRAM 작은 거에선 안 돌아간다.. 그래서 결국! 맥북에서 매우 잘 동작하는 것을 보였다고 한다.
이제 '내 손안에 비서'가 미래 이야기가 아니다. 쟈비스도 곧 구현되지 않을까?
쟈비스까지는 아니라도, 거대 언어모델을 사용하면 가짜 뉴스나 블로그 만드는 건 일도 아니다. 언어 모델을 Transfer Learning 시키면 채팅 말고도 다양한 태스크를 풀 수 있다. 물론 무료로 말이다. 그냥 쉽게 거대 언어 모델을 ChatGPT 대용으로 사용한다고 해도 이미 매우 유익하다. 개인 PC에서 돌아가니 더 이상 유료로 사용하지 않아도 되며, 공유해서 생기는 문제가 아니라면, 검열이나 규제에 대한 문제로부터도 자유로워진다.
이게 진정 무서운 이유는, 거대 언어 모델의 대중화를 앞다투어 이끌기 때문이라고 생각한다. 사람들은 이미 자신의 기기에서 ChatGPT와 같은 거대 언어 모델을 릴리즈하기 위해 경쟁하기 시작했다. 오픈 소스의 무서운 점도 바로 빠른 발전이다. 모두가 공유하며 발전시키는 코드는 명과 암이 있으나, 개발을 촉진시키는 부분도 분명히 있다. 앞으로 1년만 지나면 워치에서 돌리는 거대 언어 모델이 나올지도 모르지 않는가?
PS) 최근에는 서적 집필, 블로그 작성 등 여러 일로 바빠서 아직 보류중이지만, 좀 여유로워지면 Alpaca류의 모델을 구현해 보는 내용으로 포스팅을 계획하고 있다. 그때쯤이면 더 가벼운 모델이 나올 것으로 예상된다.
'GPT' 카테고리의 다른 글
| [신규 출간 소식] 하루만에 이해하는 챗GPT 활용법 (3) | 2023.05.17 |
|---|---|
| 범용 인공지능의 탄생?!(Auto-GPT 설치 및 사용법 포함) (1) | 2023.04.25 |
| [Q&A] GPT-3.5와 GPT-4은 뭐가 다를까? (0) | 2023.04.13 |
| AI가 코딩하는 시대에는 어떤 프로그래머가 살아남을까? (2) | 2023.03.30 |
| 책을 쓰면서 (4) | 2023.03.24 |



